
성과를 만드는 것보다 검증하는 것이 더 중요해진 시대 — 2026년 5월 AI 퀀트 연구 월간 종합
매달 쏟아지는 수백 편의 AI·퀀트 논문 중 진짜 주목할 만한 것은 무엇일까? 2026년 5월에 발표된 755편을 분석해 5가지 테마로 정리했다.
들어가며: 투자 성과를 "만드는" 것과 "믿는" 것의 차이
맛집 리뷰를 읽을 때, "별 다섯 개!"라는 점수만 보고 바로 예약하시나요? 대부분은 아닐 겁니다. 그 점수가 실제 손님 후기인지, 업체가 쓴 것인지, 혹시 평가 기준 자체가 이상한 건 아닌지 한 번쯤 의심하죠. 투자 세계에서도 비슷한 일이 벌어지고 있습니다.
2026년 5월, AI와 퀀트 연구 분야에서는 755편의 새 논문이 공개됐습니다. 이 중 우리 평가 기준을 통과한 관련 논문은 286편, 최상위 등급(S·A)은 34편이었습니다. 이 논문들을 읽으면서 발견한 가장 강렬한 메시지 하나를 먼저 전합니다.
"더 화려한 모델을 만드는 경쟁에서, 보고된 성과가 진짜인지 검증하고 감사하는 경쟁으로 옮겨가고 있다."
이번 달 유일한 최상위(S등급) 논문은 백테스트의 시간 누수를 진단하는 벤치마크였습니다. LLM 트레이딩 에이전트 분야에서는 출력 성과 대신 내부 추론 궤적의 감사가능성이 화두였고, 마켓메이킹·크립토·옵션 분야에서도 리스크의 정직한 노출과 해석가능성이 공통 규범으로 자리 잡았습니다.
자, 2026년 5월의 연구를 5가지 테마로 살펴봅시다.
테마 1: 백테스트 성과의 "진실"을 시험하는 도구
일상 비유로 시작하기
주식 투자 동호회에서 "내 전략은 연 30% 수익이 나왔어요"라고 자랑하는 글을 본 적 있으실 겁니다. 그런데 그 수익률이 "어떤 날짜 기준으로 샀는지", "당일 나온 뉴스를 미리 반영했는지"에 따라 천차만별로 달라질 수 있다는 사실, 아셨나요?
마치 요리 대회에서 "30분 안에 완성"이라고 했는데, 사실은 타이머를 시작하기 전에 재료를 다 손질해 놓은 것과 같습니다. 보고된 성과는 화려하지만, 실제 상황에서는 그만큼 나오지 않을 수 있죠.
무엇이 문제인가
AI 머신러닝으로 주식 전략을 만들 때, 보통 과거 데이터를 잘라서 "이 부분으로 학습하고, 저 부분으로 검증"합니다. 이때 검증 데이터에 학습 시점의 정보가 몰래 새어 들어가면, 성과가 실제보다 훨씬 좋아 보입니다. 이것을 "결정시점 누수(decision-time leakage)"라고 부릅니다.
예를 들어, 오전 9시 30분에 시장이 열리는데, 같은 날 오전 10시에야 알 수 있는 정보를 9시 30분 체결 가격에 반영해버리는 식입니다. 이런 위반이 하나씩 끼어들면, 백테스트 상의 샤프 비율(위험 대비 수익 지표)이 비용이 커져도 양수를 유지합니다 — 마치 "공짜 알파"처럼 보이게 만드는 거죠.
핵심 논문: When Alpha Disappears (2605.23959, S등급)
이 논문은 단순히 "누수가 문제다"라고 경고하는 데서 그치지 않습니다. "한 번에 하나의 평가 규칙만 바꿔서, 그 규칙이 성과를 얼마나 부풀렸는지 정확히 측정하는 진단 도구"를 제안합니다.
연구팀은 데이터 패널, 시계열 분할, 모델 종류, 예측 기간, 포트폴리오 규칙, 거래 비용, 성과 지표를 모두 고정한 채, 딱 하나의 평가 규약만 바꿉니다. 기준선은 깨끗한 "다음 날 시가 체결" 규약이고, 이것저것 바꿔보는 겁니다: 시계열 특징의 중심화 여부, 같은 날 시가에 장중 정보를 섞는지, 정규화 범위, 종가 청산 시점 등.
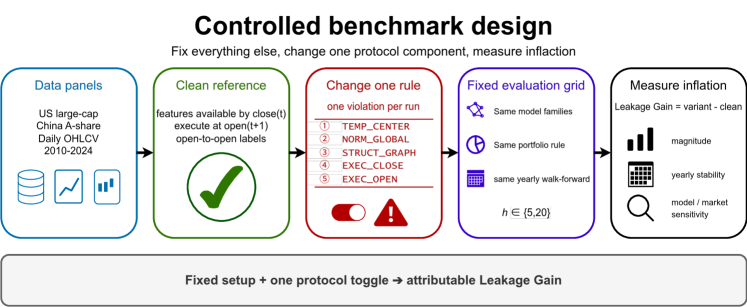
주요 발견:
- 누수는 "전부 아니면 전무"가 아니라 선택적입니다. 시계열 특징 중심화와 개장 후 정보를 섞은 시가 체결은 성과를 크고 안정적으로 부풀리지만, 전역 정규화나 종가 청산은 효과가 미미했습니다.
- 거래 비용을 점점 올렸을 때, 깨끗한 규약의 샤프 비율은 비용이 커지면서 0 근처나 아래로 무너졌습니다. 반면 두 가지 주요 위반 규약은 비용이 커져도 강하게 양수를 유지했습니다 — 즉 누수가 비용을 압도해버린 거죠.
- 이 효과는 특정 연도에만 나타나는 게 아니라 2016~2024년 전 구간에서 일관되게 관찰됐습니다.
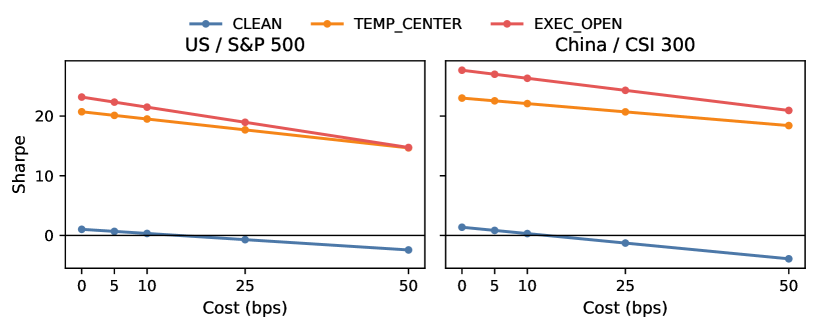
함께 보면 좋은 논문들
- The Alpha Illusion (2605.16895): LLM 트레이딩 에이전트가 보고하는 샤프·알파가 시간 무결성, 반사실 강건성, 예측 캘리브레이션을 통과하지 못하면 배포 증거로 쓰면 안 된다고 경고합니다. 백테스트 누수 문제를 LLM 에이전트 영역으로 확장한 자매 논문입니다.
- Structural Limits of OHLCV-Based Intraday Signals (2605.04004): MNQ 선물 인트라데이에서 개장 레인지 돌파, 갭, 세션 간 모멘텀 신호를 체계적으로 반증합니다. OHLCV(시가·고가·저가·종가·거래량) 데이터만으로 얻는 인트라데이 우위의 구조적 한계를 정량화했죠.
이 테마의 공통 인사이트
세 논문이 한목소리로 말하는 것이 있습니다. "보고된 알파의 상당 부분은 모델이 아니라 평가 프로토콜에서 나온다." 검증의 단위가 "전략이 좋은가"가 아니라 "이 숫자가 실제 배포 가능한 증거인가"로 옮겨가고 있습니다. 755편 중 유일한 S등급이 이 테마에서 나왔다는 사실 자체가, 현재 연구 커뮤니티가 검증의 중요성을 얼마나 높이 평가하는지 보여줍니다.
테마 2: LLM 트레이딩 에이전트 — 성과 대신 내부 추론을 감사하라
일상 비유로 시작하기
회사에서 신입 사원이 "이번 달 매출 20% 올렸습니다!"라고 보고했다고 합시다. 훌륭하죠. 그런데 "어떻게?"라고 물었을 때, "글쎄요, 그냥 느낌이 좋았어요"라고 대답하면 어떨까요? 결과는 좋았지만 과정을 신뢰할 수는 없습니다. 반면, "A 고객사의 구매 주기가 3개월에서 2개월로 단축된 데이터를 발견하고, 먼저 연락드렸더니 추가 주문이 들어왔습니다"라고 말하면, 그 성과가 지속 가능할지 판단할 수 있습니다.
LLM(대규모 언어 모델) 기반 트레이딩 에이전트도 마찬가지입니다. 수익률 숫자만으로는 신뢰할 수 없고, 내부 추론 과정이 감사 가능한지가 핵심입니다.
핵심 논문: Representation Signatures (2605.28850, A등급)
이 논문은 8개 LLM 에이전트의 트레이딩 궤적을 분석하면서, 실패 직전에 내부 표현이 어떻게 변하는지를 추적했습니다.
연구팀은 "TradeArena"라는 감사 가능한 테스트베드를 만들고, 네 가지 종류의 임베딩 프로브(해시 기반, LSA, 트랜스포머, 화이트박스 은닉상태)로 LLM의 내부 상태를 탐침했습니다.
주요 발견:
- 표현 시그니처: 실패에 앞서 "계획 임베딩이 정상 중심에서 이탈"하고, "계획-리스크 융합 표현이 정상과 드로다운 직전 상태를 분리"합니다. 성과가 나빠지기 전에 국소 매니폴드의 유효 랭크가 수축하는 패턴이 관찰됐습니다.
- 리스크-피드백 정렬: 구조화된 리스크 피드백을 주면 파인튜닝 없이도 모델의 행동이 정렬되지만, 모델마다 효과가 다릅니다.
- 상관관계 맹점: 스트레스 상황에서 LLM은 서로 관련된 자산에 동시에 노출을 키우는 경향을 보입니다. LLM의 정당화는 집중 리스크를 키우지만, 별도의 리스크 레이어가 이를 사후에 잘라내는 구조가 필요합니다.
- 실험 규모는 인트라데이 51개 종목, 8개 트래젝토리입니다.
FundaPod: 사람이 검증 가능한 에이전트 설계
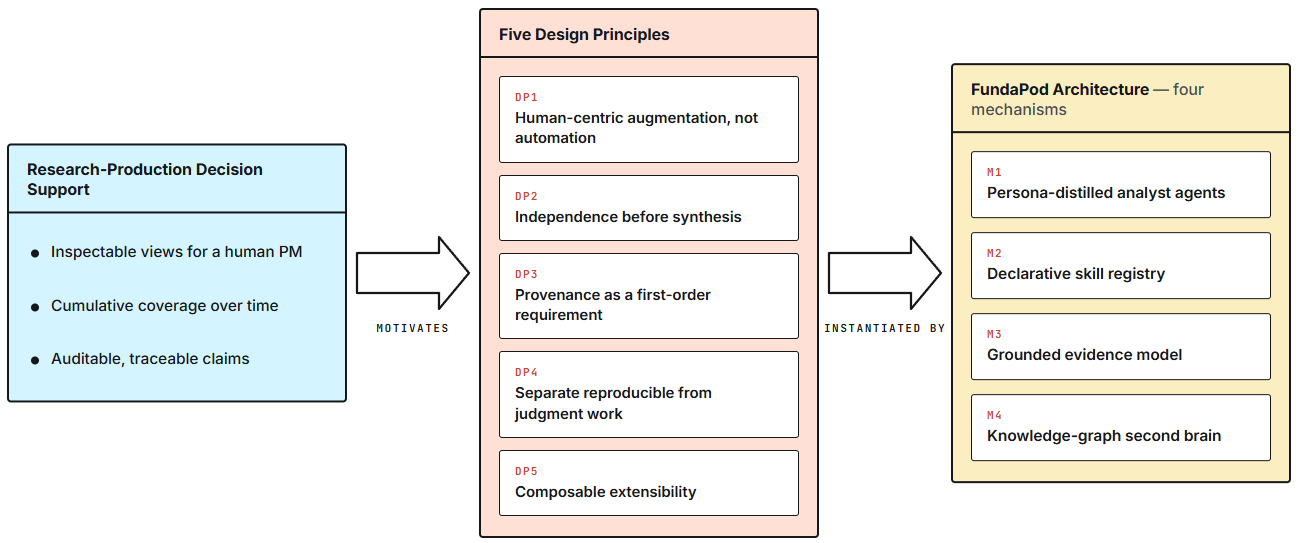
FundaPod (2605.27864)는 지식그래프 메모리와 다중 페르소나 에이전트로 펀더멘털 리서치를 보조하는 플랫폼입니다. 핵심은 사람이 읽고 검증할 산출물을 남기는 구조를 만든다는 점입니다. 투자 메모, 비즈니스 드라이버 분석, 증거 수집 결과가 구조화된 형태로 기록되어, 나중에 "왜 이런 판단을 했는지"를 추적할 수 있습니다.
SHARP (2605.06822)는 프롬프트 최적화로 "사람이 감사 가능한 루브릭 정책"을 스스로 진화시킵니다. 비정상(non-stationary) 시장에서 크레딧 할당 문제를 다루면서도, 판단 근거를 사람이 검증할 수 있는 형태로 유지합니다.
이 테마의 공통 인사이트
세 논문이 수렴하는 메시지는 분명합니다. "LLM 에이전트를 신뢰하려면 출력 성과가 아니라 내부 추론·근거의 감사가능성을 봐야 한다." 성과 수치는 부풀려지기 쉽고(테마 1에서 확인했듯이), 진짜 가치는 실패 직전의 내부 표현 변화를 잡아내거나, 사람이 검증 가능한 근거와 메모를 남기는 구조에 있습니다.
테마 3: 마켓메이킹과 최적 집행 — 리스크를 정면으로 다루는 호가 전략
일상 비유로 시작하기
중고차 매매상을 운영한다고 상상해 보세요. 고객이 차를 사러 오면, 적절한 가격을 불러야 합니다. 너무 비싸면 안 팔리고, 너무 싸면 손해죠. 그런데 더 복잡한 문제가 있습니다. 차가 계속 쌓이면 보험료·주차비가 늘어나고(재고 리스크), 시세가 떨어질 위험도 있죠. 반대로 차가 너무 없으면 영업을 못 합니다.
마켓메이킹도 이와 같습니다. 금융시장에서 "이 가격에 사겠습니다, 이 가격에 팔겠습니다"라고 동시에 호가를 내는 역할을 하는데, 여기서 재고 리스크, 체결 확률, 적대적 선택(정보를 가진 상대에게 손해를 보는 상황)을 동시에 고려해야 합니다.
핵심 논문: Entropy-Regularized Bellman Policies (2605.24878, A등급)
이 논문은 리스크 민감 마켓메이킹을 위한 수학적 프레임을 제시합니다. 쉽게 말하면, "호가 설정에서 재고 리스크 회피와 탐색(무작위성을 통한 학습)을 하나의 파라미터로 일관되게 조절하는 방법"입니다.
기존에는 마켓메이킹 호가를 정하는 데 단순한 스프레드 휴리스틱(경험적 공식)을 썼습니다. 이 논문은 지수 효용 함수와 함께 "확실성 등가(certainty-equivalent) 점수에 로그-섬-엑스(log-sum-exp) 정규화를 적용하는 이산 엔트로피 Bellman 연산자"를 제안합니다. 어려워 보이지만, 핵심은 두 가지입니다:
- 엔트로피 파라미터(λ) 하나로 재고 리스크 회피程度와 호가의 무작위성(탐색)을 동시에 조절할 수 있습니다.
- 비싼 "정확한" 최적 정책 대신, 저비용 Hamiltonian-Gibbs 프록시로 실시간 호가를 근사할 수 있습니다.
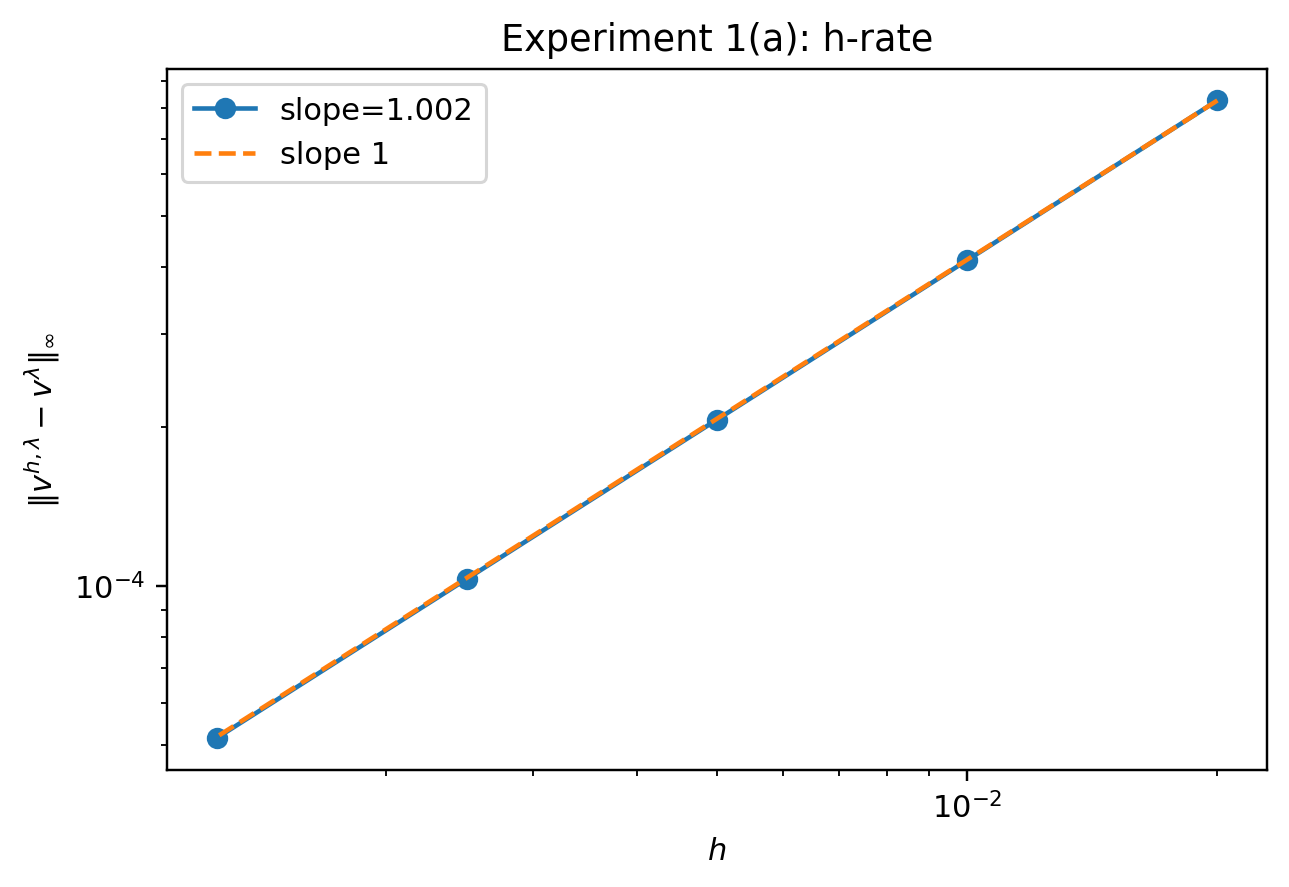
이론적 결과:
- 비정규화 연속시간 위험민감 가치 함수로의 수렴률이 O(h + λ(1+|log λ|)) 임을 증명했습니다. (h는 시간 스텝 크기, λ는 엔트로피 파라미터)
- 목표 함수에 지수 효용과 함께 종말 및 진행 중 재고 패널티를 전 구간에 걸어, 재고 리스크를 처음부터 끝까지 관리합니다.
- 검증은 Avellaneda-Stoikov 설정(고전적 마켓메이킹 모델)에서의 수치 실험에 의존하며, 실제 시장에서의 강건성은 아직 탐색되지 않았습니다.
함께 보면 좋은 논문들
- Quality-Adjusted Hit-Ratio Targeting (2605.30643): 회사채 RFQ(견적 요청) 마켓메이킹에서 "품질 보정 체결률" 타깃팅으로 적대적 선택과 마크아웃을 함께 다룹니다. 채권 시장 버전의 리스크 민감 호가입니다.
- Explicit Signal-Adaptive Sequential Optimal Execution Quotes (2605.24242): 가격에 영향을 주는 신호를 반영한 순차 최적집행 호가의 명시적 해를 제시합니다. 가격 충격, 재고, 집행 리스크를 신호에 적응시킵니다.
이 테마의 공통 인사이트
이 테마 논문들은 "호가/집행을 재고·체결확률·적대적 선택을 함께 다루는 제어 문제로 풀되, 정책의 정확성과 해석가능성을 동시에 확보한다"는 방향으로 모입니다. 단순한 스프레드 공식이 아니라, 리스크 민감 최적 제어와 신호 적응이 호가에 직접 들어가는 시대입니다.
테마 4: 크립토·DeFi의 숨겨진 미시구조 — 펀딩, 청산, 조작을 1급 변수로
일상 비유로 시작하기
전통적인 주식시장에서는 "앞에 보이는 가격"이 거의 전부입니다. 하지만 암호화폐 영구선물 시장에서는 보이지 않는 비용이 있습니다. 바로 "펀딩 비용"입니다. 쉽게 말하면, 매수 포지션과 매도 포지션 사이에 주고받는 이자 같은 것인데, 시장 분위기에 따라 크기가 크게 달라집니다.
마치 전세 시장에서 "보증금은 같지만 관리비가 천차만별인 아파트"를 고르는 것과 같습니다. 표면적인 가격만 보고 들어갔다가 숨겨진 비용에 당황할 수 있죠.
핵심 논문: Funding-Aware Optimal Market Making (2605.06405, A등급)
이 논문은 영구선물 DEX(탈중앙화 거래소) 마켓메이킹을 "재고와 펀딩이 결합된 제어 문제"로 정식화합니다.
기존 마켓메이킹 모델은 재고를 "마크투마켓(market-to-market) 익스포저"로만 봤습니다. 하지만 영구선물에서는 재고가 곧 상태 의존 펀딩 캐시플로를 만듭니다. 펀딩 비용이 양수(+)면 매수 포지션이 매도 포지션에 돈을 주고, 음수(-)면 그 반대입니다. 이 펀딩 비용이 시시때때로 변하기 때문에, 호가 설정에 직접 반영해야 합니다.
방법론:
- 펀딩레이트를 고정 파라미터가 아니라 확률 상태변수로 모델링합니다.
- Hyperliquid 거래소의 ETH, BTC, SOL 영구선물 실제 데이터로 가우시안 오른스타인-울렌벡(OU) 펀딩 모델을 보정했습니다.
- 단조 유한차분 HJB(해밀턴-야코비-벨만) 스킴으로 최적 호가를 계산합니다.
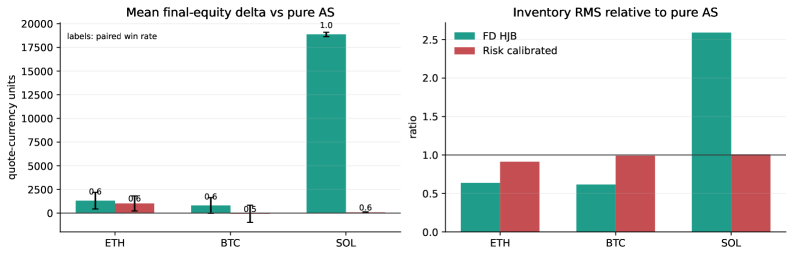
핵심 결과:
- 100개 시드 홀드아웃에서 ETH와 BTC는 펀딩 인지 HJB가 고전 방식 대비 평균 성과를 개선하고 재고 RMS를 낮췄습니다.
- SOL은 고전 방식 대비 양수이지만, 리스크 보정까지 포함하면 파레토 개선(어느 하나도 나빠지지 않는 개선)은 아닙니다.
- 가우시안 OU 모델은 펀딩의 꼬리 리스크를 과소평가하는 경향이 있어, 향후 점프 성분 추가가 필요하다고 저자 스스로 지적합니다.
함께 보면 좋은 논문들
- PumpSense (2605.09431): 텔레그램에서 벌어지는 펌프·덤프(가격 조작)를 실시간으로 탐지하고 타깃 코인을 추출합니다. 28만 개 이상의 텔레그램 포스트와 39개 조작 그룹 데이터를 분석한 NLP 프레임워크입니다. 이벤트 기반 리스크 회피와 이상거래 모니터링에 직결됩니다.
- Resolution-Aware Perpetual Futures on Binary Prediction Markets (2605.10400): 이진 예측시장 위 영구선물의 만기 붕괴와 해소 리스크를 인식한 실증 리스크 설계를 제안합니다. 인덱스 추정, 마진, 펀딩 규칙, 레버리지 스케줄을 함께 다룹니다.
이 테마의 공통 인사이트
이 테마 논문들이 공통으로 말하는 것은 "크립토·DeFi의 고유 구조를 정면으로 모델링하면 전통시장에 없던 알파와 리스크 신호가 나온다"는 것입니다. 펀딩, 청산, 조작이 더 이상 부수적 변수가 아니라 1급 상태변수로 호가와 리스크 관리에 직접 들어가고 있습니다.
테마 5: 옵션·변동성 — 딥헤징이 실제로 무엇을 배우는가
일상 비유로 시작하기
비 오는 날 우산을 쓸 때, 우산의 각도를 미세하게 조절하면서 비를 피하는 사람이 있습니다. 수학적으로 "최적"인 각도를 계속 계산하면서요. 그런데 그 사람이 갑자기 폭풍우를 만나면, 미세 조절이 무의미해집니다. 우산을 접고 실내로 들어가는 게 나을 수도 있죠.
딥헤징(Deep Hedging)도 비슷한 딜레마에 직면합니다. 딥러닝으로 옵션 헤지 비율을 학습하면 평시에는 블랙숄즈 모델보다 나을 수 있지만, 특정 시장 환경(레짐)에서는 예상 밖으로 실패할 수 있습니다.
핵심 논문: What Does Deep Hedging Actually Learn? (2605.21696, A등급)
이 논문의 질문은 직설적입니다. "딥헤징 모델이 실제로 무엇을 학습했고, 어디서 무너지는가?"
연구팀은 S&P 500 지수옵션에서 TD3 강화학습 에이전트를 학습하고, 동일한 옵션 에피소드에서 일별 갱신 블랙숄즈 델타 헤지와 2015~2023년 워크포워드(시간 순서대로 앞에서 학습하고 뒤에서 검증)로 비교했습니다. 학습된 신경망 정책을 심볼릭 회귀 증류로 사람이 읽을 수 있는 수식으로 변환해 아웃오브샘플 거래까지 시도했습니다.
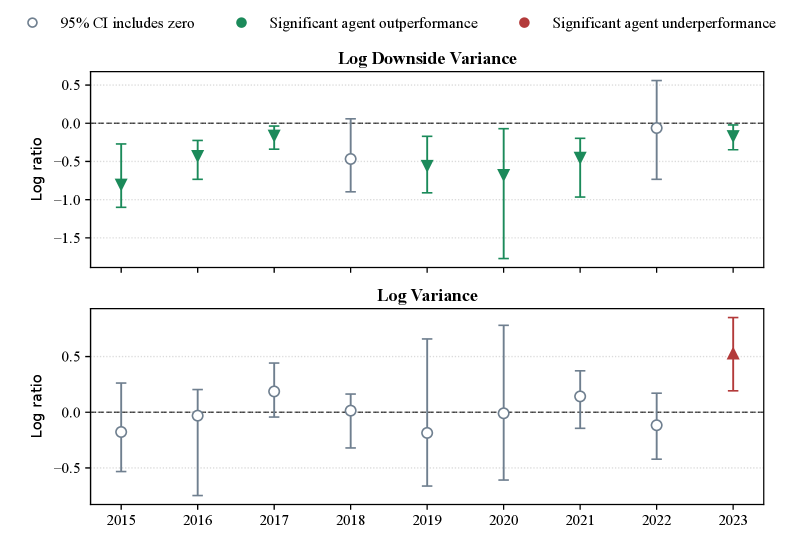
주요 발견:
- 에이전트는 블랙숄즈 대비 체계적인 델타 헤어컷(헤지 비율을 이론치보다 낮추는 방향)을 일관되게 발견했습니다. 이는 주로 현물과 내재변동성의 동조(co-movement)로 설명됩니다.
- 누적 보상과 종말 다운사이드 분산을 종종 동시에 개선합니다.
- 레짐 취약성: 2022년에는 불리한 일별 상태에서 손실이 드러났고, 2023년에는 옵션 손익이 현물에 지배적이고 변동성 채널이 약할 때 언더헤지가 일반 분산을 오히려 키웠습니다.
- 증류된 심볼릭 수식도 같은 취약성을 물려받습니다. 보상, 다운사이드 분산, CVaR(조건부 가치-at-위험) 우위는 대체로 보존되지만, 어려운 레짐에서 신뢰성이 떨어집니다.
함께 보면 좋은 논문들
- Volatility Surface Reconstruction (2605.24031): 희소한 호가 데이터에서 무차익 제약을 지키면서 내재변동성면을 재구성합니다. MLP, CNN, U-Net, VAE, 트랜스포머, SVI 등 다양한 모델을 벤치마킹합니다.
- From Arbitrage Removal to Density Extraction (2605.22792): 만기 임박 옵션에서 모델 없이도 정적 차익을 제거하고 위험중립 밀도를 추출합니다. 매수-매도 스프레드와 중간호가를 처리하는 실용적 프레임워크입니다.
이 테마의 공통 인사이트
이 테마의 논문들은 "옵션·변동성에서 딥러닝을 쓰되, 무차익 제약과 레짐 취약성을 정직하게 짚어야 한다"고 말합니다. 모델이 학습한 보정(델타 헤어컷, 변동성면 재구성)은 평시에 유효하지만, 특정 레짐에서 무너질 수 있어 해석가능성과 제약이 필수입니다.
2026년 5월의 Big Picture
이번 달 코호트 755편을 관통하는 한 문장은 "성과를 새로 만드는 경쟁에서, 보고된 성과가 진짜인지 검증하고 감사하는 경쟁으로"입니다.
| 테마 | 핵심 메시지 | 대표 논문 |
|---|---|---|
| 백테스트 검증 | 평가 프로토콜 하나가 성과를 크게 부풀린다 | 2605.23959 (S등급) |
| LLM 에이전트 | 출력 성과 대신 내부 추론의 감사가능성을 봐야 한다 | 2605.28850 |
| 마켓메이킹 | 재고·체결확률·적대적 선택을 한 제어 문제로 풀어야 한다 | 2605.24878 |
| 크립토·DeFi | 펀딩·청산·조작이 1급 상태변수다 | 2605.06405 |
| 옵션·변동성 | 딥헤징의 레짐 취약성을 정직하게 노출해야 한다 | 2605.21696 |
유일한 S등급 논문이 백테스트 누수 진단 도구였고, LLM 에이전트 분야에서는 감사가능성이 새로운 기준으로 자리 잡았습니다. 마켓메이킹과 옵션 분야에서는 리스크 민감 최적 제어와 레짐 가드레일이 공통 규범이 됐습니다.
더 화려한 모델을 만드는 것보다, 정직하게 검증되고 감사 가능한 모델을 만드는 것이 더 중요한 시대입니다.
함께하기
이 글이 유익하셨다면, 아래 링크에서 더 많은 연구 분석과 인사이트를 만나보실 수 있습니다.
- 구독: 최신 AI 퀀트 연구 분석을 이메일로 받아보세요 → ohselab.com
- 상담: 투자 전략과 시스템 구축에 대해 이야기하고 싶으시다면 → ohselab.com
- 팔로우: 새로운 글과 연구 소식을 놓치지 마세요 → ohselab.com
더 알아보기
이번 달 분석에 포함된 논문들의 arXiv 링크입니다.
| 테마 | 대표 논문 | arXiv |
|---|---|---|
| 백테스트 검증 | When Alpha Disappears | 2605.23959 |
| LLM 에이전트 | Representation Signatures | 2605.28850 |
| 마켓메이킹 | Entropy-Regularized Bellman Policies | 2605.24878 |
| 크립토·DeFi | Funding-Aware Market Making | 2605.06405 |
| 옵션·변동성 | What Does Deep Hedging Learn? | 2605.21696 |
이 글은 2026년 5월 arXiv에 공개된 755편의 AI·퀀트 관련 논문을 분석한 결과입니다. S등급 1편, A등급 33편을 포함한 286편의 관련 논문을 5개 테마로 분류하고, 각 테마의 대표 논문을 깊이 있게 분석했습니다. 모든 수치와 주장은 원문 논문에 근거하고 있으며, 투자 권유가 아닌 연구 분석 자료입니다.
관련 글

수익을 자랑하기 전에, 그 수익이 진짜인지 증명하라 — 2026년 4월 시스템 트레이딩 연구 월간 종합
2026년 4월 arXiv에 공개된 716편의 금융 AI 논문 중 252편을 분석한 월간 종합 리포트. 백테스트 검증, LLM 에이전트, 포트폴리오 최적화, 시장 미시구조, 옵션·파생까지 다섯 가지 연구 테마를 살펴봅니다.

AI가 투자 연구를 한다 — 오세랩 시스템 트레이딩 R&D 소개
오세에이아이연구소가 13개 연구 분과, 96편 논문으로 구축한 AI 기반 시스템 트레이딩 리서치 프레임워크를 소개합니다. 매일 자동 수집되는 논문에서 실전 투자 인사이트를 추출하는 과정을 공개합니다.

논문 속 숫자를 의심하라 — 2026년 3월 시스템 트레이딩 연구 월간 종합
2026년 3월 arXiv에 올라온 시스템 트레이딩·퀀트 투자 논문 734건을 분석했습니다. 백테스트 엔진 차이, LLM 시점 누수, RL 실행 현실성, MEV 경매 설계, 옵션 헤징까지 — '시뮬레이션과 실거래 사이의 괴리'를 다섯 갈래로 풀어냈습니다.