
포트폴리오가 '자신만만할수록 위험한' 이유 — 경로공간 베이지안 투자의 비밀
내 모델이 "이 주식은 오를 확률 80%"라고 말하면, 정말 그대로 믿어도 될까요?
들어가며
우리가 투자 결정을 내릴 때, 보통 이렇게 생각합니다.
"내가 분석한 결과, 이 종목의 기대수익률은 연 12%야. 그래서 자산의 30%를 넣자."
이게 표적인 '평균-분산 최적화'의 기본 아이디어입니다. 마크위츠가 1952년에 제안한 이론으로, 투자 세계에서 가장 오래되고 널리 쓰이는 프레임워크죠.
하지만 이 방법에는 치명적인 약점이 있습니다. 바로 '내 추정이 정확하다'고 무조건 믿는다는 점입니다.
현실에서는 어떨까요? 주식의 미래 수익률을 정확히 아는 사람은 아무도 없습니다. 데이터가 부족할 수도 있고, 시장 환경이 바뀔 수도 있고, 내 모델 자체에 오류가 있을 수도 있습니다. 그런데 이런 불확실성을 무시하고 "내가 추정한 값이 진짜 값"이라고 확신하면 어떻게 될까요?
바로 오늘 소개할 논문은 이 문제를 정면으로 다룹니다. "내 모델이 틀릴 가능성까지 감안해서 투자하면 어떻게 될까?"라는 질문에 수학적으로 엄밀한 답을 제시합니다.
무엇이 문제였나
기존의 포트폴리오 이론은 크게 두 갈래로 발전해 왔습니다.
첫 번째 갈래: 베이지안 투자 실제 수익률의 '진짜 평균'을 직접 알 수 없으니, 관측 데이터를 보면서 점차 학습해 나가는 접근입니다. 마치 처음에는 잘 모르지만, 시간이 지나면서 점차 감을 잡아가는 투자자처럼요. 이때 흔히 쓰는 도구가 '칼만 필터(Kalman-Bucy filter)'입니다 — 불확실한 평균 수익률을 실시간으로 추정해 주는 수학적 장치입니다.
두 번째 갈래: 강건한(robust) 투자 "내 모델이 틀릴 수 있다"는 가능성을 명시적으로 반영합니다. '최악의 시나리오'를 상정하고, 그 최악에서도 견딜 수 있는 전략을 찾습니다. Hansen과 Sargent가 발전시킨 프레임워크인데, 경제학에서는 이미 널리 쓰입니다.
문제는 이 두 갈래가 따로 놀았다는 것입니다.
베이지안 투자자는 "나는 학습하면서 투자한다"고 말하지만, 자기 추정이 틀릴 가능성은 고려하지 않았습니다. 반대로 강건한 투자자는 "모델이 틀릴 수 있다"고 걱정하지만, 학습 과정을 제대로 반영하지 못했습니다.
마치 한쪽은 "열심히 공부하면 시험 잘 볼 수 있어!"라고 자신만만하고, 다른 쪽은 "아무리 공부해도 시험은 불확실해!"라고 걱정만 하는 것과 같습니다. 둘 다 맞는 말인데, 둘을 합치지 못했던 거죠.
핵심 아이디어
이 논문은 바로 이 두 갈래를 하나로 통합합니다. 그것도 매우 우아한 방법으로요.
'이중 채널'의 발견
논문의 가장 중요한 발견은 이렇습니다:
주식의 실제 움직임(드리프트)과 투자자의 믿음(추정값)이 같은 원인에 의해 흔들린다는 것.
좀 더 쉽게 설명하면 이렇습니다. 투자자가 주식의 평균 수익률을 추정할 때, 시장의 가격 변동 데이터를 관측합니다. 그런데 이 관측 데이터가 왜곡되면 어떻게 될까요?
- 채널 1: 실제 주식 수익률이 왜곡된 데이터에 영향을 받음
- 채널 2: 투자자의 추정(학습 결과)도 같은 왜곡된 데이터에 영향을 받음
하나의 충격이 두 갈래로 나뉘어 투자자를 동시에 공격하는 셈입니다. 마치 하나의 돌멩이가 물에 떨어져 파동이 양쪽으로 퍼지듯요.
이 구조를 논문은 '이중 채널(dual-channel)'이라고 부릅니다. 이전 연구들은 이 두 채널을 따로 분석했지만, 이 논문은 둘을 동시에 고려합니다.
보수적 투자자처럼 행동하라
그러면 이런 '이중 채널 위험'에 어떻게 대응할까요?
논문의 해법은 놀랍도록 직관적입니다: 큰 베팅을 할수록 훨씬 더 큰 벌금을 매겨라.
구체적으로, 포지션 크기(투자 비율)에 대해 '세제곱 보정항(cubic correction)'을 추가합니다. 쉽게 말하면:
- 투자를 적게 할 때 → 원래 전략과 거의 차이 없음
- 투자를 많이 할 때 → 원래 전략보다 매우 보수적으로 만듦
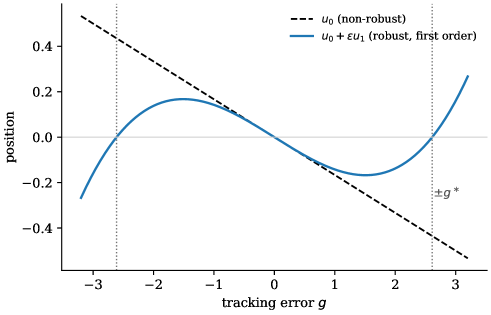
이 그림을 보면, 점선(원래 전략)과 실선(강건 전략)의 차이가 포지션이 클수록 훨씬 커지는 것을 볼 수 있습니다. 마치 "자신만만하게 큰돈을 걸면, 그에 비례해서 더 세게 브레이크를 밟는" 것과 같습니다.
왜 세제곱일까요? 이중 채널 구조 때문입니다. 하나의 채널만 있었으면 제곱으로 끝났겠지만, 두 채널이 곱해지면서 세제곱이 됩니다. 이 논문의 이론적 핵심이 여기 있습니다.
'추정 리스크'의 역설
흥미로운 발견이 하나 더 있습니다.
드리프트(평균 수익률)를 이미 정확히 알고 있다고 가정하면, 강건한 보정 비용이 무한대가 됩니다. 즉, "나는 이미 다 아는데, 혹시 틀릴 수도 있다"고 걱정하면 보수가 극단적으로 커진다는 뜻입니다.
반면, 드리프트를 데이터로 학습하는 상황에서는 보정 비용이 유한합니다. 왜냐하면 학습 과정 자체가 불확실성을 줄여주기 때문입니다.
쉽게 말하면, "나는 아직 모르지만 열심히 배우고 있다"는 태도가, "나는 다 안다고 생각한다"는 태도보다 오히려 더 안전하다는 역설입니다. 배움의 과정 자체가 불확실성을 정규화(regularize)해 주는 셈입니다.
결과 — 무엇을 알아냈나
논문은 수학적 증명 위주이므로 대규모 실증 실험은 아니지만, 핵심 결과를 정리하면 이렇습니다:
-
강건한 가격(the robustness price): 모형 불확실성의 '값'을 정량화할 수 있는 명시적 수식 제시. 이전까지 이런 공식이 없었습니다.
-
포지션 사이즈 규칙: 기존 포트폴리오 비중에 큐빅 보정항을 더하면 강건한 전략이 됩니다. 수식 자체는 간단해서 실전에 바로 적용할 수 있습니다.
-
학습이 불확실성을 정규화: 데이터로 학습하는 상황에서는 강건한 보정 비용이 유한하다는 것이 증명되었습니다. 이는 "학습이 모형 오류의 충격을 자연스럽게 완화한다"는 실용적 통찰을 제공합니다.
-
Value-scaling 보존: 투자자의 위험 회피도가 변해도 포트폴리오의 기본 구조(affine 정책)가 유지된다는 것을 보였습니다.
한계와 주의점
솔직하게 말씀드리면, 이 논문에는 몇 가지 한계가 있습니다.
- 단일 자산 가정: 지금은 주식 하나 + 무위험 자산(예: 국채)이라는 단순한 설정입니다. 현실의 다자산 포트폴리오로 확장하려면 추가 연구가 필요합니다.
- 연속시간, 지수적 효용 함수: 수학적 편의를 위해 특수한 가정을 사용했습니다. 다른 형태의 효용 함수에서는 결과가 달라질 수 있습니다.
- 수치 실험 제한적: 논문의 주요 기여는 이론적 증명이고, 실증 데이터를 활용한 대규모 검증은 아직 부족합니다.
- 거래 비용 미반영: 실제 투자에서 중요한 매매 비용은 모형에 포함되지 않았습니다.
그럼에도 불구하고, 이 논문이 제공하는 수학적 프레임워크 자체는 매우 가치 있습니다. 추후 다자산, 거래 비용, 다른 효용 함수로 확장하는 후속 연구의 토대가 될 수 있기 때문입니다.
그래서 투자/실무엔?
일반 투자자분들도 이 논문에서 얻을 수 있는 교훈은 분명합니다.
1. "내 모델이 맞을 수도 있지만, 틀릴 수도 있다"는 사실을 항상 기억하세요.
포트폴리오를 구성할 때, 추정값을 그대로 믿고 전액 투자하기보다는, 추정의 불확실성을 감안해서 조금 더 보수적으로 투자하는 것이 장기적으로 안전합니다. 이 논문은 그 '보수적 정도'를 수학적으로 정량화해 줍니다.
2. 자신만만할수록 위험합니다.
논문의 큐빅 보정항은 "큰 베팅 = 큰 위험"이라는 것을 수학적으로 증명합니다. 확신이 강할수록 불확실성에 대한 보정도 강해져야 합니다.
3. 학습이 곧 헤지입니다.
데이터를 꾸준히 관찰하고 모델을 업데이트하는 '학습' 과정 자체가 모형 불확실성을 줄여줍니다. "한 번 최적화하고 끝"이 아니라, 지속적으로 추정을 갱신하는 것이 중요합니다.
4. 실전 알고리즘 트레이딩에서의 활용
카만 필터 기반 온라인 드리프트 추정 + 평균-분산 최적화를 사용하는 알고리즘 트레이딩 시스템이라면, 이 논문이 제공하는 큐빅 보정 수식을 포지션 사이징에 바로 통합할 수 있습니다.
더 알아보기
- 📄 원 논문: arXiv:2606.24212
관련 논문
- Bayesian Parametric Portfolio Policies (arXiv:2602.21173) — PPP의 정책 불확실성을 베이지안으로 보정하는 유사 접근
- Stochastic Discount Factors with Cross-Asset Spillovers (arXiv:2602.20856) — 자산 간 상호작용을 반영한 가격결정 모형
이 글은 arXiv 프리프린트(동료 검증 전)를 기반으로 작성되었습니다. 실험 결과는 특정 조건에서의 수치이며, 실제 투자 성과를 보장하지 않습니다.
참고: 이 글은 일반적인 정보 제공 목적이며, 구체적인 사안은 전문가와 상담하시기 바랍니다.
관련 글

수익을 자랑하기 전에, 그 수익이 진짜인지 증명하라 — 2026년 4월 시스템 트레이딩 연구 월간 종합
2026년 4월 arXiv에 공개된 716편의 금융 AI 논문 중 252편을 분석한 월간 종합 리포트. 백테스트 검증, LLM 에이전트, 포트폴리오 최적화, 시장 미시구조, 옵션·파생까지 다섯 가지 연구 테마를 살펴봅니다.

AI가 투자 연구를 한다 — 오세랩 시스템 트레이딩 R&D 소개
오세에이아이연구소가 13개 연구 분과, 96편 논문으로 구축한 AI 기반 시스템 트레이딩 리서치 프레임워크를 소개합니다. 매일 자동 수집되는 논문에서 실전 투자 인사이트를 추출하는 과정을 공개합니다.

논문 속 숫자를 의심하라 — 2026년 3월 시스템 트레이딩 연구 월간 종합
2026년 3월 arXiv에 올라온 시스템 트레이딩·퀀트 투자 논문 734건을 분석했습니다. 백테스트 엔진 차이, LLM 시점 누수, RL 실행 현실성, MEV 경매 설계, 옵션 헤징까지 — '시뮬레이션과 실거래 사이의 괴리'를 다섯 갈래로 풀어냈습니다.