
2025년 12월 AI 금융 연구 동향: 크립토 파생상품의 학술적 성숙, 그리고 "틀렸을 때를 잡는 AI"
2025년 12월, arXiv에 올라온 금융 AI 논문 531건을 분석한 결과입니다. 크립토 시장의 핵심 인프라가 학술적 형식화의 대상이 되기 시작했고, LLM의 금융 침투에 따른 "신뢰성" 문제가 새로운 연구 분야로 자리잡았습니다.
들어가며: 2025년 12월, 두 가지 물음
2025년 12월은 금융 AI 연구에서 의미 있는 전환점이었습니다. 한쪽에서는 비트코인이 사상 최고가를 갱신하는 가운데 크립토 파생상품 시장이 60조 달러 규모로 성장했고, 다른 한쪽에서는 대형 언어 모델(LLM)이 애널리스트 리서치, 스트레스 테스트, 거래 에이전트 등 금융 의사결정의 구석구석에 침투하고 있었습니다.
이 두 흐름이 만나면서 두 가지 질문이 동시에 제기되었습니다. 첫째, "크립토 거래소의 손실 사회화 메커니즘은 정말 공정한가?" 둘째, "LLM이 금융에서 틀렸을 때, 그걸 잡을 수 있는가?"
2025년 12월 코호트(2512)에 등록된 214건의 관련 논문 중 A등급 23건을 중심으로, 이 달의 연구를 5개 테마로 정리합니다.
테마 1: 크립토 파생상품과 거래소 인프라의 학술적 정식화
왜 흥미로운가?
비트코인 퍼페추얼 선물(perpetual futures)은 하루 거래량이 수백억 달러에 이르는 거대한 시장입니다. 그런데 이 시장을 움직이는 핵심 메커니즘 — 포지션 청산(liquidation)과 자동차감(ADL, Autodeleveraging) — 이 학술적으로 거의 연구된 적이 없었습니다. 마치 자동차 엔진이 만들어진 지 10년이 지났는데, 아직 물리학 교과서에 실리지 않은 것과 같습니다.
2025년 12월, 이 공백이 동시에 여러 연구팀에 의해 채워지기 시작했습니다.
대표 논문: ADL은 "공정하게" 할 수 있을까?
타룬 치트라(Gauntlet 연구소)가 발표한 이 논문은 ADL을 처음으로 게임이론적 프레임워크로 형식화했습니다. ADL이 뭔지 쉽게 설명하면 이렇습니다.
퍼페추얼 선물에서 레버리지 거래를 하다가 시장이 급격히 움직이면, 먼저 '청산'(포지션 강제 종료)이 발생합니다. 그런데 청산으로도 담보가 부족하면, 거래소는 이긴 쪽 트레이더의 수익을 깎아서 손실을 메웁니다. 이것이 ADL입니다. 이긴 사람이 졌으니까 돈을 떼이는 것인데, 과연 이게 "적절한" 수준으로 이루어질까요?
논문은 이를 스택켈베르크 게임으로 모델링했습니다. 거래소가 '리더'(규칙을 정하는 쪽), 트레이더가 '팔로워'(반응하는 쪽)인 구조입니다.
핵심 발견: ADL의 트릴레마
이 논문이 밝혀낸 가장 중요한 결과는 불가능 정리(Trilemma)입니다.
어떤 ADL 정책이든 세 가지 목표를 동시에 만족시킬 수 없습니다:
- 상환능력(solvency): 거래소가 파산하지 않음
- 수익(revenue): 거래소가 돈을 벌 수 있음
- 공정성(fairness): 손실이 참여자에게 고르게 분배됨
마치 레스토랑에서 음식 품질, 가격, 서비스를 모두 완벽하게 하는 것이 불가능한 것처럼, ADL에서도 이 세 가지 사이의 트레이드오프가 수학적으로 증명된 것입니다.
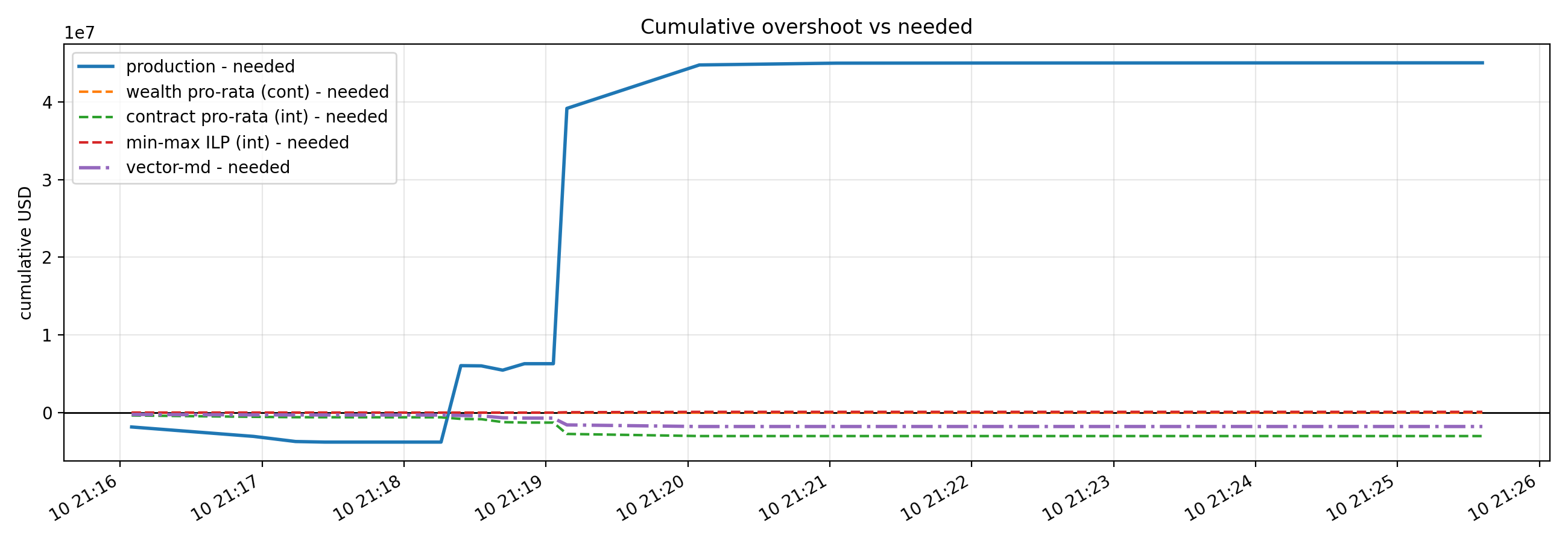
실제 사태: 2025년 10월 10일 Hyperliquid 사건
이론이 아니라 실제 데이터도 있습니다. 2025년 10월 10일, Hyperliquid 거래소에서 12분 만에 21억 달러 규모의 포지션이 청산되었습니다. 논문은 이 사건을 '두 패스 리플레이'로 재구성하여 분석했습니다.
결과는 충격적이었습니다:
- Hyperliquid의 실제 ADL 알고리즘은 필요한 최소 손실보다 과도하게 오버슈트
- 수익 트레이더의 초과 손실: 4,500만~5,170만 달러
- Binance는 Hyperliquid보다 ADL을 훨씬 과다하게 사용
이 테마의 공통 인사이트
12월에 발표된 크립토 파생상품 연구들은 한 가지를 분명히 말합니다. 크립토 시장의 핵심 인프라가 더 이상 '실무자의 직감'에만 의존할 수 없는 단계에 왔다는 것입니다. ADL, 퍼페추얼 선물 백테스트, DEX 유동성 — 이 모든 것이 게임이론, 최적화 이론으로 정식화되기 시작했습니다.
추가 논문으로 AutoQuant(거래 비용을 강제 반영한 크립토 백테스트 감사 프레임워크)와 Equilibrium Liquidity in DEX(DEX 유동성 공급의 내생적 균형 분석)도 같은 맥락에서 주목할 만합니다.
테마 2: 포트폴리오 최적화와 모델 독립적 가격결정
왜 흥미로운가?
투자은행에서 옵션 가격을 매길 때, 블랙숄즈 모델부터 헤스턴, 로컬볼까지 여러 모델을 씁니다. 그런데 이상하게도, 서로 다른 모델을 써도 엑조틱 파생상품(배리어 옵션 같은 복잡한 상품)의 가격이 비슷하게 나옵니다. 왜 그럴까요? 이 질문에 답하는 논문이 12월에 등장했습니다.
대표 논문: "어떤 모델을 써도 비슷한 가격"의 수학적 설명
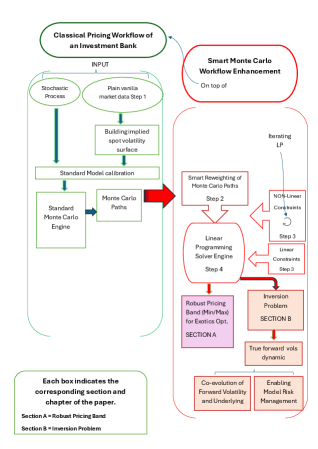
이 논문은 기존 몬테카를로 가격결정 인프라 위에 경로 재가중치(path reweighting)와 원뿔 최적화(conic optimisation) 레이어를 오버레이로 추가하는 프레임워크를 제안합니다.
쉽게 말하면, 이미 돌리고 있는 시뮬레이션 코드를 건드리지 않고, 위에 한 겹 덧씌워서 모델 간 가격 차이를 정량화하는 방법입니다. 기존 코드를 바꿀 필요 없이 '모델 리스크 관리 레이어'를 붙이는 셈입니다.
핵심 발견은 이겁니다: 바닐라 옵션 표면(시장에서 관찰되는 기본 가격)에 맞춘 서로 다른 모델들의 엑조틱 가격이 좁은 밴드 안에 수렴한다는 것입니다. 마치 서로 다른 경로로 산을 올라도 정상에서 만나는 것과 같습니다.
이 테마의 공통 인사이트
12월 포트폴리오 연구들은 "모델을 더 복잡하게 만드는 것"보다 "어떤 모델을 쓰더라도 결과가 얼마나 달라지는가"를 정량화하는 것이 더 중요해지고 있음을 보여줍니다. 베이지안 불확실성 정량화(Index-Tracking Bayesian Sparse Portfolio), LLM 기반 스트레스 시나리오 생성(LLM Counterfactual Stress Scenarios), Wasserstein 분포강건 최적화(Bayesian DRO Merton Problem) 등 다양한 방법론이 같은 방향을 가리키고 있습니다.
테마 3: LLM의 금융 침투, 그리고 "신뢰성" 문제
왜 흥미로운가?
LLM이 금융에서 할 수 있는 일이 빠르게 늘고 있습니다. 애널리스트 리서치 보조, 스트레스 시나리오 생성, 거래 에이전트 — 응용 범위가 넓어지면서 한 가지 문제가 점점 더 두드러집니다. 바로 "LLM이 틀렸을 때"입니다. 금융에서는 환각(hallucination)이 단순한 불편함이 아니라 실제 손실로 직결될 수 있습니다.
대표 논문: AI-Trader — 실시간 시장에서 에이전트를 벤치마킹하다
이 논문은 LLM 기반 트레이딩 에이전트가 실제 시장 데이터 스트림에서 어떻게 의사결정하는지를 체계적으로 평가하는 프레임워크를 제시합니다. 기존 연구가 시뮬레이션 환경에서 에이전트를 테스트했다면, 이 논문은 실시간 환경으로 무대를 옮겼습니다.
핵심 발견은 기존 벤치마크(시뮬레이션)와 실제 시장 환경 사이에 상당한 성능 갭이 존재한다는 것입니다. 에이전트의 도구 호출 정확도, 시장 적응성, 위험 인식이 실제 환경에서 어떻게 변하는지를 정량적으로 측정했습니다.
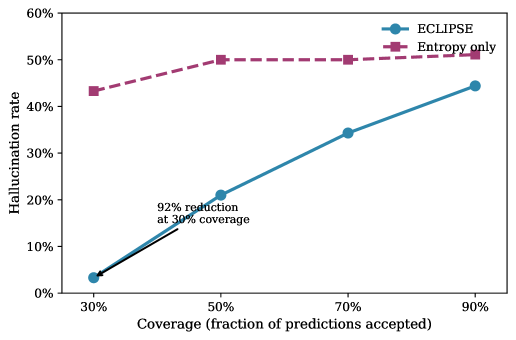
환각을 92% 줄이는 방법: ECLIPSE
더 흥미로운 연구는 LLM의 환각을 체계적으로 탐지하는 방법론입니다. ECLIPSE는 LLM의 환각을 '의미 엔트로피 대비 증거 용량'의 불일치로 정식화합니다.
쉽게 말하면, LLM이 답변할 때 그 답이 얼마나 "확신에 차 있는지"(엔트로피)와 주어진 증거를 얼마나 "잘 활용했는지"(용량)를 비교하는 것입니다. 확신은 넘치는데 증거를 제대로 안 쓴 답변, 바로 환각입니다.
금융 QA 데이터셋에서 ECLIPSE는 환각률을 92% 감소시켰습니다. 30% 커버리지 기준으로 기존 방법(entropy-only)은 43.3%의 환각률을 보였지만, ECLIPSE는 3.3%로 떨어졌습니다.
신경기호적 검증: VERAFI
VERAFI는 한 단계 더 나아갑니다. RAG(Retrieval-Augmented Generation)의 한계 — 계산 오류, 규정 위반 — 를 신경기호적(neurosymbolic) 정책 생성으로 보완합니다. GAAP나 SEC 규정 같은 복잡한 규칙을 SMT-LIB 형식으로 변환하여 LLM 출력을 형식적으로 검증합니다. 사실 정확도가 52.4%에서 94.7%로 개선되었습니다.
이 테마의 공통 인사이트
12월 LLM 연구의 핵심 메시지는 명확합니다. "AI가 틀렸을 때를 잡는 AI"가 새로운 연구 분야로 자리잡았다는 것입니다. 환각 탐지(ECLIPSE), 룩어헤드 편향 검출(LAP), 신경기호적 검증(VERAFI) — LLM의 실패 모드를 체계적으로 다루는 연구가 집중적으로 등장한 것이 이 달의 가장 두드러진 특징입니다.
테마 4: 강화학습과 연속시간 포트폴리오 제어
왜 흥미로운가?
포트폴리오를 관리한다는 것은 매 순간 "얼마를 어디에 넣을지"를 결정하는 것입니다. 이 결정이 연속적으로 이루어진다는 점에서, 포트폴리오 문제는 본질적으로 연속시간 제어 문제입니다. 그런데 대부분의 강화학습(RL) 연구는 이산시간(하루, 한 시간 단위)에서 이루어져 왔습니다.
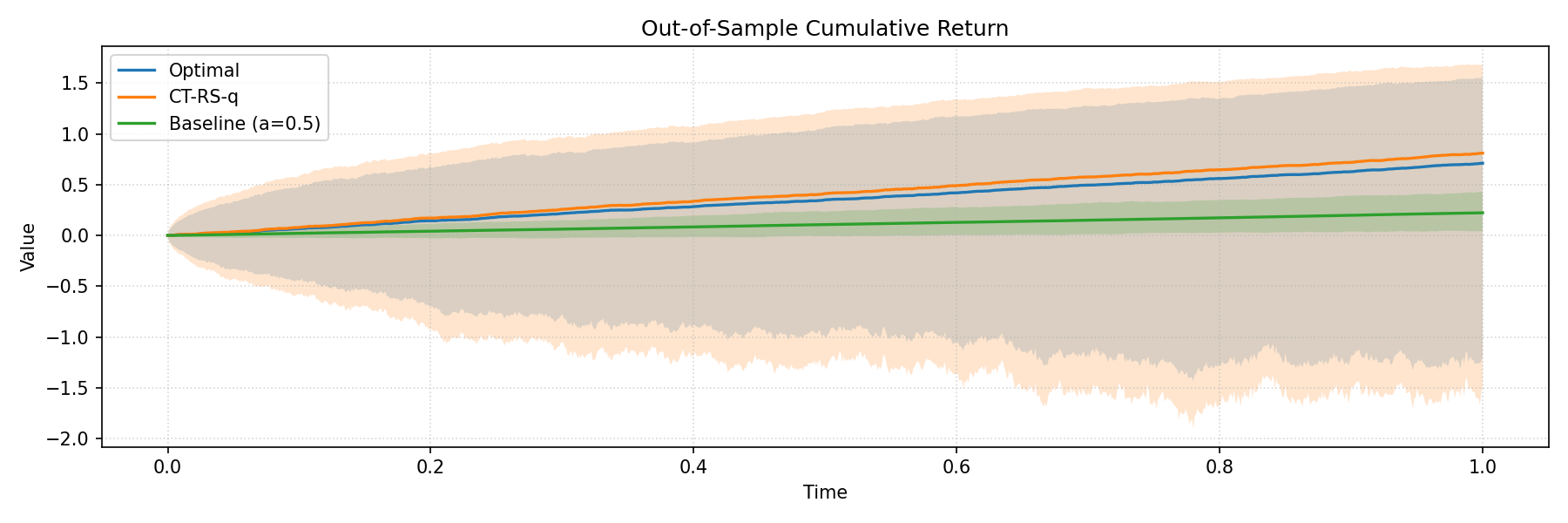
대표 논문: 위험민감 Q-러닝의 연속시간 버전
이 논문은 연속시간 확률미분방정식(SDE) 환경에서 OCE(Optimized Certainty Equivalent) 기반 위험민감 Q-learning을 연구합니다.
OCE가 뭔지 쉽게 설명하면, 기대 수익만 보는 것이 아니라 "나쁜 상황에서 얼마나 나쁜가"도 함께 고려하는 보상 척도입니다. 예를 들어 기대값이 10% 수익인데, 최악의 경우 50% 손실이 나는 전략과, 기대값이 8% 수익인데 최악의 경우 10% 손실만 나는 전략이 있다면, 위험민감한 투자자는 후자를 선호할 것입니다.
논문의 핵심 기여는 마르코프성 정리입니다. OCE 함수형을 써도 최적 정책이 "현재 상태에만 의존하는"(마르코프) 정책임을 증명한 것입니다. 이는 이론적으로 중요합니다 — 비선형 함수형에서는 마르코프성이 깨질 수 있기 때문입니다.
이 테마의 공통 인사이트
12월 RL 연구들은 위험(risk)과 불확실성(uncertainty)을 RL 목표에 직접 통합하려는 추세가 뚜렷함을 보여줍니다. 거래비용과 포지션 한도를 반영한 실전형 헤징(Deep Hedging with RL), HJB 기반 최적 집행에서 PINN의 한계를 보완한 연구(MT-PINN), 내부 리스크와 전이 불확실성을 분리한 강건 동적계획(Robust Bayesian DP) 등 — 이론과 실전의 간극이 좁아지고 있습니다.
테마 5: 비정상성과 변동성의 새로운 모델링
왜 흥미로운가?
주식시장은 변합니다. 2020년 3월의 시장과 2021년 12월의 시장은 완전히 다른 세계입니다. 그런데 대부분의 예측 모델은 "시장이 변하지 않는다"는 가정 위에 세워져 있습니다. 이 가정이 틀렸다면? 더 정확하게, "시장이 얼마나 변하는가"에 따라 어떤 모델을 써야 하는지가 달라진다면?
대표 논문: 비정상성-복잡도 상충관계
이 논문은 주가수익률 예측에서 비정상성-복잡도 상충관계(nonstationarity-complexity tradeoff)를 처음으로 정식화합니다.
핵심 아이디어는 이렇습니다:
- 복잡한 모델은 데이터를 잘 맞추지만(낮은 specification error), 긴 학습 창이 필요
- 긴 학습 창 = 더 오래된 데이터를 사용 = 시장이 더 많이 변함 = 비정상성이 강해짐
- 따라서 모델이 복잡해질수록 비정상성에 취약해지는 상충관계가 존재
논문은 이 상충관계를 해결하기 위해 토너먼트 절차(tournament procedure)를 제안합니다. 여러 후보 모델 클래스와 학습 창 크기를 동시에 최적화하는 방법입니다.
놀라운 실증 결과
17개 산업 포트폴리오 수익률 대상 실험에서:
- OOS R-square이 평균 14~23% 개선 (표준 롤링 윈도우 대비)
- NBER 경기침체 기간에서 특히 강력한 성능
- 경제적 가치: 제안 방법 기반 전략은 누적 수익 31% 향상
이 테마의 공통 인사이트
12월 계량경제 연구들은 "비정상성은 잡음이 아니라 구조"라는 인식이 확산되고 있음을 보여줍니다. 변동성을 3차원으로 분해한 연구(3D Volatility Memory Decomposition), 무차익 옵션 표면을 직접 구축한 연구(Arbitrage-Free Option Surface), 단조성 제약의 정확도 비용을 정량화한 연구(Monotone Gradient Boosting) 등 — 전통 계량경제학의 형식화 수준이 한 단계 더 정교해졌습니다.
2025년 12월의 큰 그림
12월 코호트를 관통하는 세 가지 흐름이 있습니다.
첫째, 크립토 인프라의 학술적 성숙. ADL, 퍼페추얼 선물 백테스트, DEX 유동성 등 크립토 시장의 핵심 인프라가 게임이론·최적화 이론으로 정식화되기 시작했습니다. 60조 달러 시장이 학술적 연구 대상으로 본격 편입된 시점입니다.
둘째, LLM의 금융 침투와 "신뢰성" 위기. LLM 에이전트가 금융 의사결정에 실질적으로 침투하면서, 환각 탐지, 룩어헤드 편향 검출, 신경기호적 검증 등 "AI가 틀렸을 때를 잡는 AI" 연구가 새로운 분야로 자리잡았습니다.
셋째, 비정상성의 중심부로. 모델 선택, 변동성 모델링, 포트폴리오 최적화 전반에서 "비정상성은 잡음이 아니라 구조"라는 인식이 확산되고 있습니다.
더 알아보기
이 글에서 다룬 논문들의 arXiv 링크입니다.
이 블로그는 자동 수집·평가 파이프라인의 결과를 바탕으로 작성되었습니다.
참고: 이 글은 일반적인 정보 제공 목적이며, 구체적인 사안은 전문가와 상담하시기 바랍니다.
관련 글

상품선물에 그래프를 입혔다 — 만기별 가격 관계를 학습하는 캘린더 스프레드 AI
상품선물의 상품-계약 계층 구조를 그래프 신경망으로 모델링해 캘린더 스프레드 전략의 수익성을 크게 높인 Northwestern대 연구를 쉽게 풀어 설명합니다.

포트폴리오가 '자신만만할수록 위험한' 이유 — 경로공간 베이지안 투자의 비밀
추정한 투자 전략이 얼마나 틀릴 수 있는지까지 감안하는 '강건한 베이지안 포트폴리오' 방법론을 일상 비유와 함께 쉽게 풀어 설명합니다.
AI가 주식을 예측할 때, '기억'하고 있었다면? — MemGuard-Alpha로 LLM 알파의 함정을 걸러내는 방법
대형 언어 모델(LLM)이 금융 데이터를 '기억'해서 만든 허위 알파 신호를 실시간으로 걸러내는 MemGuard-Alpha 프레임워크를 소개합니다. Sharpe 비율 49% 개선, 오염 신호 대비 7배 수익 차이의 핵심 원리를 쉽게 풀어 설명합니다.