
2025년 8월 AI 트레이딩 연구 한눈에 보기: 금융 데이터에 특화된 AI가 온다
"일반 AI로 금융을 하면 성능이 떨어진다"는 건 이제 상식이 됐습니다. 이번 달은 그 상식을 정면으로 돌파하려는 논문들이 유독 많았어요.
들어가며: 일반 AI에서 금융 전용 AI로
인공지능이 모든 분야를 바꾸고 있지만, 금융은 좀 특별합니다. 주식 차트의 캔들스틱은 일반 시계열과 생김새가 다르고, 변동성은 시간에 따라 계속 변하고, 서로 다른 자산끼리의 관계도 시시각각 달라지거든요. 그래서 GPT 같은 범용 AI를 금융에 그대로 쓰면, 생각만큼 성능이 안 나오는 경우가 많습니다.
2025년 8월, arXiv에서 시스템 트레이딩·퀀트 투자와 관련된 논문 170편을 수집해 평가했습니다. 전부 관련 있는 것으로 판정되었고, 27편이 A등급을 받았습니다. S등급은 없었지만, 그게 오히려 의미 있는 숫자입니다 — "최고 한 편의 발견"이 아니라 전 분야에 걸친 균형 잡힌 성숙을 보여주기 때문이에요.
이번 달을 5개 연구 테마로 정리했습니다.
테마 1: 금융 차트를 읽는 전용 AI, Kronos
왜 흥미로운가?
비트코인이나 주식 차트를 본 적이 있으신가요? 빨간색과 파란색 막대가 위아래로 오가는 걸 "캔들스틱" 또는 "K-line"이라고 부릅니다. 이 차트는 일반 시계열(예: 온도 변화, 심박수)과는 많이 달라요. 가격·거래량·시가·종가가 한데 묶여 있고, 자산마다, 거래소마다 패턴이 다릅니다.
지금까지 나온 AI 시계열 모델은 대부분 "일반 시계열"에 맞춰져 있어서, 금융 K-line 데이터에 적용하면 생각만큼 성능이 안 나왔습니다. 마치 영어를 배운 AI에게 한국어 시를 분석하라고 하는 것과 비슷해요.
이번 달의 핵심 논문
2508.02739 Kronos 논문은 이 문제를 정면으로 해결했습니다.
핵심 아이디어는 두 가지예요:
-
금융 전용 토크나이저 만들기: 캔들스틱 데이터를 AI가 이해할 수 있는 숫자 조각(토큰)으로 바꾸는 변환기를 새로 설계했어요. Transformer 기반으로, 가격의 움직임과 거래 활동 패턴을 모두 보존하는 계층적 토큰을 만듭니다.
-
120억 개 이상의 K-line으로 사전학습: 전 세계 45개 거래소에서 수집한 120억 개가 넘는 K-line 데이터로 AI를 미리 학습시켰습니다. 마치 GPT가 인터넷의 모든 텍스트로 학습하듯이, Kronos는 전 세계 금융 차트로 학습한 거예요.
놀라운 결과: 기존 최고 모델 대비 가격 예측 능력(RankIC)이 93% 향상되고, 변동성 예측 오차는 9% 줄었으며, 합성 차트 생성 품질은 22% 개선됐습니다. 이 세 가지를 하나의 모델로 다 할 수 있다는 게 핵심이에요.
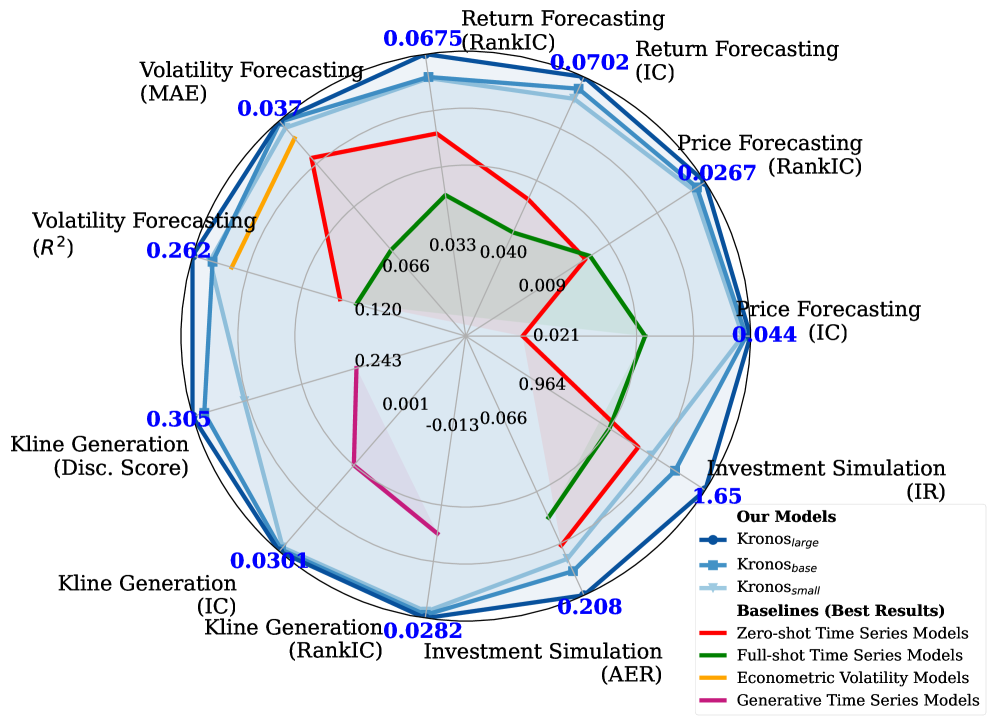

함께 보면 좋은 논문들
- FinCast (2508.19609): 금융 시계열 전용 파운데이션 모델로, 종목·자산군·주기 차이를 넘어 제로샷(별도 학습 없이 바로 적용) 예측을 노립니다.
- 시간가변 팩터 변동성 예측 (2508.01880): 변동성의 공통 구조를 시간에 따라 변하는 팩터로 압축해, 통계 모델과 AI 예측기 모두를 강화합니다. 미국 대형 기술주와 주요 크립토에서 성능이 크게 개선됐어요.
공통 인사이트: "일반 AI를 금융에 쓰면 성능이 떨어진다"는 문제를 정면으로 해결하려는 논문들이 늘고 있습니다. 금융 데이터의 구조적 특성을 모델 자체에 반영하는 방향으로 무게추가 이동하고 있어요.
테마 2: 탈중앙 거래소의 손실 구조, 옵션 이론으로 풀다
왜 흥미로운가?
비트코인이나 이더리움을 탈중앙 거래소(DEX)에서 사고팔아 보신 적이 있으신가요? 그 뒤에는 자동화된 시장 조성자(AMM)라는 시스템이 돌아가고 있습니다. 간단히 말하면, "돈을 넣어두면 수수료를 받는 구조"인데요, 문제는 변동성이 높아지면 손해를 볼 수도 있다는 거예요. 이 손실을 "LVR(Loss-Versus-Rebalancing)"이라고 부릅니다.
지금까지 LVR은 대략적인 시뮬레이션으로만 추정했어요. 정확한 수학적 구조가 밝혀지지 않았던 거죠.
이번 달의 핵심 논문
2508.02971 논문은 AMM의 LVR을 옵션 이론으로 완전히 재해석했습니다.
핵심 발견은 놀랍습니다: AMM에 돈을 넣어두는 행위는, 본질적으로 영구 옵션을 매도하는 것과 수학적으로 같다는 거예요. 구체적으로, LVR은 이 영구 옵션의 "시간가치 감소(세타)"와 해석적으로 동일합니다.
이게 무슨 의미냐면, 유동성 제공자는 자신도 모르게 옵션을 팔고 있었고, 그 손실 구조를 옵션 가격 공식으로 정확하게 계산할 수 있게 된 거예요. 이를 통해 "어느 가격대에서 유동성을 놓으면 손실이 일정하게 유지되는지"를 수학적으로 계산할 수 있습니다.
함께 보면 좋은 논문들
- Performative Market Making (2508.04344): 시장 모델이 시장을 바꾸는 "performativity" 현상을 마켓메이킹에 정식화. 지배적 전략을 역추적해 경쟁적 호가와 초과 수익을 동시에 노리는 프레임을 제시합니다.
- AMM 최적 수수료 (2508.08152): AMM 수수료를 고정값이 아니라 변동성·거래량에 따라 실시간으로 조절하는 게 최적임을 보여줍니다. 정상 시장에서는 CEX 거래비용과 비슷하게 안정적이고, 고변동성 시기에는 높은 수수료로 유동성 공급자를 보호해요.
- rough Heston의 가짜 캘리브레이션 (2508.15080): 옵션 가격 모델에서 수치 오차가 "좋아 보이는" 캘리브레이션을 만들어낼 수 있음을 정면으로 보여줍니다. "ghost calibration"이라는 개념으로, 더 정확한 가격기를 쓰면 좋은 적합이 사라진다는 충격적인 발견이에요.
- 예측시장 차익거래 (2508.03474): Polymarket이라는 예측시장에서 종속 자산 간 가격 불일치를 체계적으로 찾아, 실현된 차익거래 이익이 약 4,000만 달러에 달함을 보여줍니다.
공통 인사이트: 시장의 미시구조를 수학적으로 정식화하고, 그 결과를 실행 가능한 설계 규칙으로 바꾸는 논문들이 늘고 있습니다. "어떻게 더 정교한 모델을 만들까"에서 "어떻게 이 모델을 실제로 쓸 수 있을까"로 무게추가 이동하고 있어요.
테마 3: 포트폴리오 최적화, 예측이 아닌 결정을 직접 개선하다
왜 흥미로운가?
포트폴리오 최적화는 퀀트 투자의 기본 중 기본입니다. "어떤 주식에 얼마나 투자할까?"를 수학적으로 푸는 문제인데요, 보통은 먼저 수익률과 변동성을 예측하고, 그 예측값을 바탕으로 최적 비중을 구합니다.
문제는, 예측이 정확하더라도 최적 포트폴리오가 안 나올 수 있다는 거예요. 예측 오차를 줄이는 것과 투자 결정을 잘하는 것은 다른 목표거든요.
이번 달의 핵심 논문
2508.10776 논문은 이 문제를 정면으로 다룹니다. "예측 오차를 줄이자"가 아니라 "투자 결정 자체를 직접 최적화하자"는 접근법입니다.
기존 방법은 공분산 행렬(자산 간 관계를 나타내는 표)을 추정할 때, MSE(평균제곱오차)를 최소화합니다. 하지만 MSE가 낮다고 해서 포트폴리오 성능이 반드시 좋아지는 건 아니에요. 이 논문은 Decision-Focused Learning(DFL)이라는 접근법으로, 공분산 추정의 그래디언트를 포트폴리오 성능 기준으로 직접 계산합니다.
실증 결과는 인상적입니다. 기존 MSE 기반 방법들이 실전에서 최적 배분을 못 만드는 경우가 있는 반면, DFL 기반 방법은 일관되게 우수한 성능을 보였어요. 특히 비선형 변수를 추가했을 때 그 효과가 크게 나타났습니다.

함께 보면 좋은 논문들
- 스테이블코인 준비자산 최적 운용 (2508.09429): 스테이블코인(달러에 고정된 암호화폐)의 준비자산을 연속시간 최적제어로 운용하는 프레임워크. 현금과 국채 비중, 민팅/리딤 수수료를 함께 최적화합니다.
- 옵션을 활용한 인덱스 추종 강화 (2508.21192): 옵션을 "인공 자산"처럼 다루는 개념을 도입해, 주식+지수옵션을 결합한 포트폴리오의 실전 성능을 개선합니다.
- 대출 조건 최적화를 위한 인과추정 (2508.02183): 신용한도·금리·대출기간처럼 여러 조건을 동시에 다루는 인과추정 방법에 단조성 제약을 결합해, 대출의 리스크-수익 최적화에 바로 연결합니다.
- 변수선택으로 최소분산 포트폴리오 개선 (2508.14986): 4,610개 기업 특성 변수 중 최소분산 포트폴리오에 실제로 도움이 되는 변수를 데이터 기반으로 선택. 임의적으로 변수를 줄이는 것보다 훨씬 나은 결과를 보여줍니다.
공통 인사이트: 포트폴리오 최적화의 "추정 오차"와 "현실 제약"을 함께 다루는 논문들이 수렴하고 있습니다. "수학적으로 최적인 것"과 "실제로 구현할 수 있는 것"의 간극을 좁히는 데 초점이 맞춰져 있어요.
테마 4: AI의 숨은 편향, 메커니즘 수준으로 파헤치다
왜 흥미로운가?
요즘 로보어드바이저나 AI 트레이딩 에이전트에 GPT 같은 대형 언어 모델(LLM)을 쓰는 경우가 늘고 있습니다. "포트폴리오를 추천해 줘"라고 물으면 LLM이 자산 배분을 해주는 거죠.
그런데 이 AI가 특정 자산이나 특정 위치의 정보를 무의식적으로 더 중요하게 여긴다면요? 예를 들어, 보고서 맨 앞에 나오는 정보를 더 신뢰하거나(primacy effect), 맨 뒤에 나오는 정보를 더 기억하거나(recency effect) 하는 거예요. 이런 "positional bias"가 금융 의사결정에 영향을 미칠 수 있습니다.
이번 달의 핵심 논문
2508.18427 논문은 이 문제를 메커니즘 수준으로 파고들었습니다.
Qwen2.5 모델(1.5B~14B)을 대상으로, 금융 이진 의사결정에서의 위치 편향을 체계적으로 검증했어요. 세 가지 방법을 사용했습니다:
- Direct Logit Attribution: 모델의 각 레이어에서 편향이 어디서 발생하는지 추적
- Head Ablation: 특정 뉴런을 끄고 켜면서 편향에 대한 기여를 측정
- Win-rate 분석: 모델 크기와 프롬프트에 따른 편향 패턴 비교
놀라운 발견이 나왔습니다: positional bias가 보편적이고, 모델 크기에 민감하며, 정교한 프롬프트 설계에서도 재부상한다는 거예요. 특히 리스크가 높은 상황에서 primacy effect와 recency effect가 새로운 취약성을 드러냈습니다.

함께 보면 좋은 논문들
- LLM으로 금융 트윗 감성 분석 (2508.07408): LLM으로 금융 트윗의 이벤트 유형을 투명하게 라벨링해 해석 가능한 감성 팩터로 변환. 특정 이벤트가 일관되게 음의 알파를 생성하는 것을 발견하고, 모든 코드를 공개했습니다.
- ContestTrade (2508.00554): LLM 트레이딩 에이전트에 내부 경쟁 메커니즘을 도입. 여러 에이전트가 경쟁하고, 시장 피드백으로 실시간 평가해 최상위 에이전트만 채택하는 구조입니다. 시장 노이즈에 대한 강건성이 크게 향상됐어요.
- THEME (2508.16936): 테마-종목의 계층 관계와 수익률 정보를 함께 학습해, 테마 투자에 맞는 종목 표현을 만듭니다. 일반 LLM 임베딩보다 테마 자산 검색 성능이 크게 개선됐어요.
공통 인사이트: "더 좋은 모델을 만들자"가 아니라 "이 결과를 믿을 수 있는가"를 묻는 논문들이 중심이 되고 있습니다. 검증의 단위가 "전략이 좋은가"에서 "이 숫자가 배포 가능한 증거인가"로 이동하고 있어요.
테마 5: 합성 데이터와 알파 평가의 혁신
왜 흥미로운가?
퀀트 트레이딩에서 "좋은 데이터"와 "좋은 평가 방법"은 성공의 두 축입니다. 하지만 실제 금융 데이터는 비싸고 제한적이며, 알파(초과 수익)를 평가하려면 백테스트를 수없이 돌려야 해서 시간이 오래 걸립니다.
이번 달은 이 두 문제를 동시에 해결하려는 논문들이 눈에 띄었습니다.
이번 달의 핵심 논문
2508.02758 CTBench 논문은 암호화폐 도메인에 특화된 최초의 시계열 생성 벤치마크입니다.
기존 시계열 생성 모델 평가는 주로 "통계적으로 비슷한가"만 봤어요. 하지만 CTBench는 여기서 한 걸음 더 나아가 "합성 데이터로 실제 트레이딩을 하면 수익이 나오는가"까지 평가합니다.
452개 암호화폐 토큰의 데이터를 모아서, 5개 방법론 계열의 8개 모델을 4개 시장 체제에서 비교했어요. 핵심 발견은 통계적 충실도와 실제 수익성 사이에 트레이드오프가 존재한다는 것입니다. 즉, 원래 데이터와 통계적으로 가장 비슷한 합성 데이터가 반드시 가장 수익성이 좋은 건 아니라는 뜻이에요.
함께 보면 좋은 논문들
- 경로 시그니처 기반 헤징 (2508.02759): 경로 시그니처라는 수학적 도구를 헤징에 결합해, LSTM보다 적은 계산으로 더 안정적인 비마르코프 헤징 전략을 제시합니다.
- AlphaEval (2508.13174): 백테스트 없이 알파의 5개 차원(예측력, 안정성, 강건성, 금융 논리, 다양성)을 병렬 평가하는 프레임워크. 알파 마이닝의 병목인 평가 비용과 편향을 크게 줄입니다.
- ESG 리스크 변수 식별 (2508.18679): 계층적 ESG 원천변수에서 변동성 리스크와 직접 연결되는 항목을 추려내는 프레임워크. 집계 ESG 점수보다 원천 변수가 재무 리스크에 훨씬 더 관련이 있음을 보여줍니다.
공통 인사이트: "더 좋은 데이터"와 "더 효율적인 평가"라는 두 목표가 하나로 수렴하고 있습니다. 합성 데이터의 품질을 "실제 트레이딩 성과"로 측정하고, 알파 평가를 "백테스트 없이" 수행하는 방향으로 진화하고 있어요.
월 전체 Big Picture
2025년 8월의 2508 코호트를 관통하는 메시지는 "파운데이션 모델과 전통 수학의 양방향 침투"입니다.
한쪽에서는 Kronos와 FinCast가 "금융 데이터에 특화된 대규모 사전학습 모델"을 통해 제로샷 예측·변동성 예측·합성 데이터 생성을 하나로 묶고 있습니다. 다른 쪽에서는 rough Heston의 가짜 캘리브레이션을 해부하고, AMM의 LVR을 옵션 이론으로 재해석하고, GMVP의 공분산 추정을 의사결정 최적화로 바꾸는 논문들이 전통 수학의 정밀함을 새로운 문제 정식화에 적용하는 방향을 보여주고 있어요.
LLM 영역에서는 "더 좋은 모델"이 아니라 "이 결과를 믿을 수 있는가"라는 질문이 중심이 되었습니다. positional bias 감사, 이벤트 감성 팩터의 투명성, 내부 경쟁 메커니즘 등 검증·감사·견제 장치에 대한 연구가 활발합니다.
S등급이 없는 대신 A등급 27편이 고르게 분포한 것도 같은 맥락이에요. "최고 한 편의 발견"이 아니라 "전 분야에 걸친 실무 적용성의 성숙"이 이 달의 성격입니다.
함께하기
이런 연구 동향을 더 깊이 추적하고 싶으시다면?
- OHSE AI Lab: https://ohselab.com — 시스템 트레이딩·퀀트 투자 연구 커뮤니티
- 최신 논문 분석과 리서치 인사이트를 매주 업데이트합니다
- 궁금한 점이 있으시면 언제든 문의해 주세요
더 알아보기
| 논문 | 분과 | 티어 | composite | 핵심 키워드 |
|---|---|---|---|---|
| 2508.02739 Kronos | C1 | A | 79.7 | 파운데이션 모델, K-line 토크나이저, 제로샷 |
| 2508.15080 rough Heston | B4 | A | 78.8 | ghost calibration, SINH-acceleration |
| 2508.02758 CTBench | C5 | A | 76.9 | 크립토 TSG 벤치마크, 이중 태스크 |
| 2508.10776 DFL-GMVP | B3 | A | 76.2 | 의사결정 직접 최적화, 공분산 추정 |
| 2508.09429 Stablecoin | B3 | A | 74.2 | 준비자산 최적제어, 연 구조 |
| 2508.01880 Factor Vol | B4 | A | 73.7 | 시간가변 팩터, 변동성 예측 |
| 2508.02759 Signatures | C2 | A | 72.5 | 경로 시그니처, 비마르코프 헤징 |
| 2508.13174 AlphaEval | A2 | A | 72.5 | 알파 평가, 5차원, 백테스트 프리 |
| 2508.18427 Bias Audit | C4 | A | 71.9 | positional bias, 메커니즘 해석 |
| 2508.07408 Sentiment | C3 | A | 71.9 | 이벤트 감성 팩터, LLM 라벨링 |
| 2508.02971 LVR Options | A4 | A | 69.8 | AMM LVR, 연속납입 옵션 |
| 2508.00554 ContestTrade | C4 | A | 68.6 | 다중 에이전트, 내부 경쟁 |
| 2508.16936 THEME | B1 | A | 67.9 | 테마 투자, 대조 학습 |
관련 글

2026년 6월 AI 트레이딩 연구 한눈에 보기: 이론과 실무를 꿰매는 달
2026년 6월 arXiv에서 발굴한 AI 트레이딩·퀀트 투자 논문 151편을 5개 연구 테마로 정리. AMM 수수료 최적 제어, 신경망 옵션 가격의 오차 상계, LLM 자산 편향 감사, 기관 포트폴리오 GPU 가속, 강화학습의 경제적 해석까지.

120억 개 캔들차트로 배운 AI, 주식·비트코인·환율까지 꿰뚫다 — Kronos 파운데이션 모델
45개 거래소, 120억 개 K-line 데이터로 사전학습한 금융 시계열 파운데이션 모델 Kronos를 소개합니다. 가격 예측, 변동성 예측, 합성 데이터 생성을 하나의 모델로 제로샷 처리하는 구조와 실전 시사점을 쉽게 풀어 설명합니다.

포트폴리오가 '자신만만할수록 위험한' 이유 — 경로공간 베이지안 투자의 비밀
추정한 투자 전략이 얼마나 틀릴 수 있는지까지 감안하는 '강건한 베이지안 포트폴리오' 방법론을 일상 비유와 함께 쉽게 풀어 설명합니다.